현재 추천 시스템에서 가장 중요한 모델 유형 중 하나는 두 개의 탑(tower)을 가진 신경망입니다. 이 신경망의 구조는 다음과 같습니다: 신경망의 한 부분(탑)은 질의(사용자, 맥락)에 대한 모든 정보를 처리하며, 다른 탑은 객체에 대한 정보를 처리합니다. 이 두 탑의 출력은 임베딩인데, 이것은 곱셈(내적 또는 코사인, 여기서 이미 논의한 바와 같이)으로 처리됩니다. 이러한 네트워크의 추천을 위한 적용에 대한 첫 번째 언급은 YouTube에 관한 매우 좋은 논문에서 찾아볼 수 있습니다. 그런데 이제 이 논문을 추천 분야에 입문하는 데 가장 적합하고 클래식하다고 할 수 있겠습니다.

이러한 네트워크의 특징은 무엇일까요? 이들은 행렬 분해와 매우 유사한데, 행렬 분해는 사실 사용자 ID와 아이템 ID만 입력으로 받는 특수한 경우입니다. 하지만, 임의의 네트워크와 비교할 때, 두 탑에서 나온 입력이 최종 단계까지 융합되지 않도록 하는 '늦은 교차 제한' 때문에 두 탑 네트워크는 응용에서 매우 효율적입니다. 단일 사용자에 대한 추천을 구축하기 위해서는 질의 탑을 한 번 계산하고, 이 임베딩을 보통 사전에 계산된 문서의 임베딩과 곱해야 합니다. 이 과정은 매우 빠릅니다. 또한, 이러한 사전 계산된 문서 임베딩은 ANN 인덱스(예: HNSW)로 구성될 수 있어 전체 데이터베이스를 검색하지 않고도 좋은 후보를 빠르게 찾을 수 있습니다.
사용자 부분을 모든 쿼리마다 계산하는 대신 일정한 주기로 비동기적으로 계산함으로써 효율성을 더욱 향상시킬 수 있습니다. 그러나 이는 실시간 히스토리와 맥락을 고려하는 것을 희생하는 것을 의미합니다.
탑 자체는 상당히 복잡할 수 있습니다. 예를 들어, 사용자 부분에서는 히스토리를 처리하기 위해 셀프 어텐션 메커니즘을 사용할 수 있으며, 이는 개인화를 위한 트랜스포머로 이어집니다. 그러나 늦은 교차 제한을 도입하는 비용은 무엇일까요? 당연히 이는 품질에 영향을 미칩니다. 같은 어텐션 메커니즘에서, 우리가 현재 추천하고자 하는 아이템을 사용할 수 없습니다. 이상적으로는 사용자의 히스토리에서 유사한 아이템에 집중하고 싶어합니다. 따라서 초기 교차가 있는 네트워크는 일반적으로 랭킹의 후반 단계에서 사용되며, 후보가 수십 또는 수백 개만 남아 있을 때 사용됩니다. 반면, 늦은 교차(두 탑)가 있는 네트워크는 초기 단계와 후보 생성에 사용됩니다.
(그러나 이론적인 주장에 따르면, 충분한 차원의 임베딩을 통해 다양한 쿼리에 대한 문서의 합리적인 순위를 인코딩할 수 있습니다. 더욱이, NLP에서 디코더는 같은 원리로 작동하지만 각 토큰마다 쿼리 탑을 재계산합니다.)
Loss Functions and Negative Sampling
특히 주목할 점은 두 탑 네트워크를 훈련시키기 위해 사용되는 손실 함수입니다. 원칙적으로 이들은 다양한 결과를 목표로 하는 어떤 손실 함수로도 훈련될 수 있으며, 심지어 각 탑에서 다른 임베딩을 가진 다양한 헤드에 대해 여러 가지 다른 손실 함수를 가질 수도 있습니다. 그러나 흥미로운 변형은 배치 내 음성(negative)을 이용한 소프트맥스 손실로 훈련하는 것입니다. 데이터셋의 각 쿼리-문서 쌍에 대해, 같은 미니 배치 내의 다른 문서들이 같은 쿼리와 함께 소프트맥스 손실에서 음성으로 사용됩니다. 이 방법은 효과적인 하드 음성 마이닝 형태입니다.
하지만 이러한 손실 함수의 확률적 해석을 고려하는 것이 중요하며, 이는 항상 잘 이해되지 않습니다.
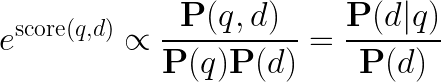
훈련된 네트워크에서, 점수의 지수는 쿼리에 따른 문서의 사전 확률이 아니라 쿼리에 특화된 PMI(점별 상호 정보량)에 비례합니다. 더 인기 있는 문서가 반드시 더 자주 추천되는 것은 아니며, 훈련 중에 이들이 음성으로 비례적으로 더 자주 나타나기 때문입니다. 점수를 특징으로 사용하는 것은 유익할 수 있지만, 최종 랭킹과 후보 생성을 위해 사용하면 매우 특정하면서도 품질이 낮은 문서로 이어질 수 있습니다.
Google은 훈련 중에 logQ 수정을 사용하여 이 문제를 해결할 것을 제안했습니다. 반면에 우리는 훈련 중이 아닌 응용 단계에서 문서의 사전 확률 P(d)을 간단히 곱하는 방법으로 이 문제를 일반적으로 해결했습니다. 그러나 이 두 접근 방식을 비교한 적은 없으며, 이는 실제로 흥미로운 비교가 될 것입니다.
Implicit Regularization: Bridging ALS and Modern Neural Networks
암시적 ALS(Implicit ALS, IALS)라는 협업 필터링 알고리즘이 있습니다. 이 알고리즘은 신경망 시대 이전에 가장 인기 있는 알고리즘 중 하나였다고 할 수 있습니다. 이 알고리즘의 특징적인 부분은 효과적인 '음성 마이닝'입니다: 상호작용 이력이 없는 모든 사용자-객체 쌍은 음성으로 처리되지만, 실제 상호작용보다는 더 적은 가중치를 받습니다. 또한, 실제 마이닝과는 달리, 이 음성들은 샘플링되지 않고 모든 반복에서 전체적으로 사용됩니다. 이 접근 방식은 암시적 정규화로 알려져 있습니다.
이것이 어떻게 가능할까요? 합리적인 작업 크기(사용자와 객체의 수)를 가정할 때, 음성의 수가 너무 많아서 나열하는 것조차 전체 훈련 과정보다 더 오래 걸릴 것 같습니다. 이 알고리즘의 아름다움은 MSE 손실과 최소 제곱법을 사용함으로써 모든 사용자와 모든 객체에 대해 각각 별도의 요소를 각 전체 반복 전에 사전 계산할 수 있으며, 이것만으로 암시적 정규화를 수행하는 데 충분하다는 데 있습니다. 이 방법으로 알고리즘은 제곱 크기를 피할 수 있습니다. (더 자세한 내용은 당시 제가 좋아하는 논문 중 하나를 참조하시기 바랍니다).
몇 년 전, 저는 이러한 암시적 정규화의 멋진 아이디어를 두 탑 신경망과 같은 더 발전된 기술과 결합할 수 있는지 고민했습니다. 이는 복잡한 질문입니다. 왜냐하면 여기에는 전체 배치가 아닌 확률적 최적화가 있고, MSE 손실로 돌아가기를 꺼리는 경향이 있기 때문입니다(적어도 전체 작업에 대해서는 그렇습니다. 정규화에 대해서는 괜찮을 수도 있지만 일반적으로 열등한 결과를 초래합니다).
오랜 시간 고민한 끝에, 드디어 해결책을 찾았습니다! 몇 주 동안 저는 이것을 시도해 볼 것을 고대하며 들떠 있었습니다.
그리고, 물론 (이런 경우에 자주 그렇듯이), 저는 누군가가 이미 세 년 전에 모든 것을 생각해냈다는 것을 한 논문에서 읽었습니다. 또 다시, 그것은 Google이었습니다. 나중에, 같은 논문에서 logQ 수정에 관한 내용에서, 그들은 암시적 정규화보다 배치 내 음성을 이용한 소프트맥스 손실이 더 나은 결과를 낸다는 것을 보여주었습니다.
이렇게 우리는 이 아이디어를 테스트하는 시간을 절약할 수 있었습니다 🙂
Do We Really Need Negative Sampling for Recommendation Models?
결국, 우리는 실제 추천 인상의 사례를 가지고 있으며, 사용자가 그것들과 상호 작용하지 않았다면, 이들을 강력한 부정적 사례로 사용할 수 있습니다. (이는 추천 서비스 자체가 아직 출시되지 않아 인상이 없는 경우를 고려하지 않습니다.)
이 질문에 대한 답은 그리 간단하지 않습니다; 이는 우리가 훈련된 모델을 어떻게 적용하려는지에 따라 달라집니다: 최종 순위 결정, 후보 생성, 또는 다른 모델에 입력할 특징으로 사용하기 위해.
실제 인상만을 가지고 모델을 훈련하면 어떻게 될까요? 상당히 강한 선택 편향이 발생하며, 모델은 특정 맥락에서 보여진 문서들만 잘 구별하게 됩니다. 보여지지 않은 문서(또는 더 정확하게는 쿼리-문서 쌍)에서는 모델의 성능이 훨씬 더 나빠질 것입니다: 어떤 문서에 대해서는 예측을 과대평가하고, 다른 문서에 대해서는 과소평가할 수 있습니다. 분명히, 이 효과는 순위 결정에서 탐색을 적용함으로써 완화될 수 있지만, 대부분의 경우 이는 부분적인 해결책에 불과합니다.
이러한 방식으로 훈련된 후보 생성기는 쿼리에 대해 문서의 풍부함을 생성할 수 있으며, 이러한 맥락에서 본 적이 없는 문서에 대해 예측을 과대평가할 수 있습니다. 이러한 문서 중에는 종종 완전한 쓰레기가 있습니다. 최종 순위 모델이 충분히 좋다면, 이 문서들을 걸러내고 사용자에게 보여주지 않을 것입니다. 그러나 우리는 여전히 불필요하게 후보 할당량을 이들에게 낭비합니다(적합한 문서가 전혀 남아 있지 않을 수도 있습니다). 따라서 후보 생성기는 대부분의 문서 기반은 품질이 낮고 추천(후보로 지명)되어서는 안 된다는 것을 이해하도록 훈련되어야 합니다. 부정적 샘플링은 이를 위한 좋은 방법입니다.
최종 순위 모델은 이 점에서 후보 생성과 매우 유사하지만 중요한 차이가 있습니다: 그들은 자신의 실수에서 배웁니다. 모델이 특정 문서에 대한 예측을 과대평가하는 실수를 할 때, 이 문서들은 사용자에게 보여지며 다음 훈련 데이터셋에 포함될 수 있습니다. 우리는 이 새로운 데이터셋에서 모델을 다시 훈련시키고 사용자에게 다시 배포할 수 있습니다. 새로운 거짓 긍정이 나타날 것입니다. 데이터셋 수집 및 재훈련 과정은 반복될 수 있으며, 이는 일종의 활동적 학습을 결과로 하며, 몇 번의 재훈련 반복만으로도 과정이 수렴하고 모델이 허위 추천을 중단하게 됩니다. 물론, 무작위 추천으로 인한 피해는 고려해야 하며, 때로는 추가 예방 조치를 취하는 것이 좋습니다. 그러나 전반적으로 여기서는 부정적 샘플링이 필요 없습니다. 오히려, 이는 탐색을 방해하여 시스템이 국소 최적에 머물게 할 수 있습니다.
모델이 다른 모델로 입력되는 특징으로 사용되는 경우, 동일한 논리가 적용되지만 무작위 후보 문서에 대한 예측을 과대평가하는 것으로 인한 피해는 다른 특징들이 최종 예측을 조정하는 데 도움이 될 수 있기 때문에 덜 중요합니다. (문서가 후보 목록에조차 오르지 않는다면, 우리는 그것에 대한 특징을 계산하지 않을 것입니다.)
한 때, 우리는 직접 테스트를 했고, 표준 ALS가 특징으로서 IALS보다 더 나은 성능을 보인다는 것을 발견했지만, 후보 생성을 위해 사용해서는 안 됩니다.
Summary
요약하자면, 우리의 탐구는 랭킹에서 두 탑 네트워크의 효과성을 강조하고, 모델 정확도에서 손실 함수와 음성 샘플링의 중요성을 검토하며, 암시적 정규화를 통해 전통적인 협업 필터링과의 간극을 메우고, 추천 시스템에서 음성 샘플링의 필수적인 역할에 대해 토론하였습니다. 이 논의는 추천 시스템 기술의 복잡성과 정교함이 진화하고 있음을 강조합니다.
'논문&아티클 리뷰(LLM + RS)' 카테고리의 다른 글
| 구글 I/O - 2024년 5월 15일 (0) | 2024.05.16 |
|---|---|
| 프롬프트 엔지니어링 방법 (0) | 2024.05.08 |
| ReAct: 언어 모델에서 추론과 행동의 시너지 효과 (0) | 2024.05.07 |
| Recommender Systems in the Era ofLarge Language Models (LLMs) (2) | 2024.05.01 |
| A Large Language Model Enhanced ConversationalRecommender System (2) | 2024.05.01 |


