[2308.06212] A Large Language Model Enhanced Conversational Recommender System (arxiv.org)
ABSTRACT
대화형 추천 시스템(CRS)은 대화 인터페이스를 통해 사용자에게 고품질의 아이템을 추천하는 것을 목표로 합니다. 일반적으로 사용자 선호도 도출, 추천, 설명, 아이템 정보 검색 등 여러 하위 작업을 포함합니다. 효과적인 CRS를 개발하기 위해서는 몇 가지 도전 과제가 있습니다: 1) 하위 작업을 어떻게 적절하게 관리할 것인가; 2) 다양한 하위 작업을 어떻게 효과적으로 해결할 것인가; 그리고 3) 사용자와 상호 작용하는 응답을 어떻게 정확하게 생성할 것인가. 최근 대규모 언어 모델(LLM)은 추론 및 생성에서 전례 없는 능력을 보여주었으며, 더욱 강력한 CRS를 개발할 새로운 기회를 제시하고 있습니다. 본 연구에서는 위와 같은 도전 과제를 해결하기 위해 새로운 LLM 기반 CRS를 제안하며, 이를 LLMCRS라고 합니다. 하위 작업 관리를 위해, 우리는 LLM의 추론 능력을 활용하여 효과적으로 하위 작업을 관리합니다. 하위 작업 해결을 위해, 우리는 LLM을 다양한 하위 작업의 전문 모델과 협력하여 성능을 향상시킵니다. 응답 생성을 위해, 우리는 사용자와의 더 나은 상호작용을 위해 언어 인터페이스로서 LLM의 생성 능력을 활용합니다. 구체적으로, LLMCRS는 하위 작업 감지, 모델 매칭, 하위 작업 실행, 응답 생성의 네 단계로 작업 흐름을 나눕니다. LLMCRS는 또한 스키마 기반 지시, 데모 기반 지시, 동적 하위 작업 및 모델 매칭, 요약 기반 생성을 디자인하여 LLM이 작업 흐름에서 원하는 결과를 생성하도록 지시합니다. 마지막으로, LLM을 대화형 추천에 적응시키기 위해, CRS 성능 피드백으로부터 강화 학습을 통한 미세 조정을 제안합니다. 이를 RLPF라고 합니다. 벤치마크 데이터셋에서의 실험 결과, LLMCRS는 RLPF와 함께 기존 방법들보다 뛰어난 성능을 보여줍니다.
CCS CONCEPTS
• Information systems → Recommender systems; Users and interactive retrieval.
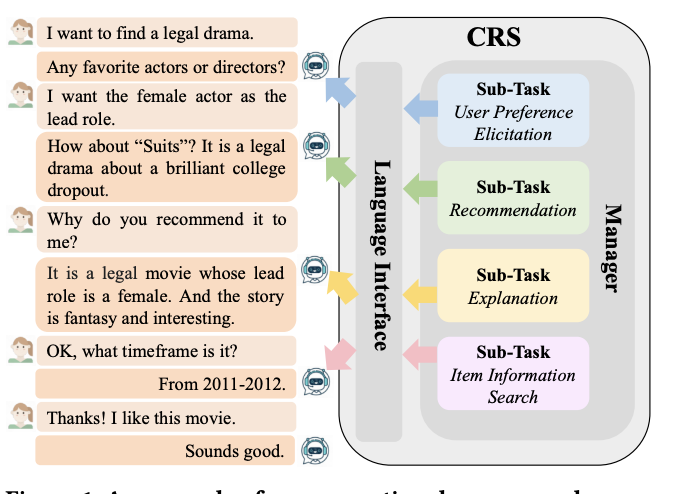
그림 1: 대화형 추천 시스템(CRS)의 예. 대화형 추천은 일반적으로 여러 하위 작업으로 구성됩니다. CRS는 하위 작업 관리 및 하위 작업 해결 능력을 가져야 합니다. 또한 사용자와 상호작용하기 위한 응답을 생성할 필요가 있습니다.
1 INTRODUCTION
최근 몇 년간 대화형 지능의 발전으로 대화형 추천 시스템(CRS)이 훨씬 더 많은 관심을 받고 있습니다. 이 시스템은 사용자 선호도 적출, 추천, 설명, 아이템 정보 검색 등 여러 하위 작업으로 구성되어 있습니다. 그림 1은 사용자가 영화 제안을 위해 에이전트에게 의존하는 CRS의 예를 보여줍니다. 사용자의 선호도를 대화형 상호 작용을 통해 적출함으로써, 시스템은 원하는 추천을 쉽게 제공할 수 있습니다. 시스템은 또한 사용자가 추천에 대해 왜 이 아이템을 추천하는지 및 아이템에 대한 더 많은 정보와 같은 질문에 대답할 수 있습니다.
더 효과적인 CRS를 개발하기 위해 해결해야 할 몇 가지 도전 과제가 있습니다: 1) 먼저, CRS는 하위 작업 관리자가 필요합니다. 일관된 대화 인터페이스에서 대화형 추천에 여러 하위 작업이 관련되어 있기 때문에, CRS는 언제 어떤 하위 작업을 수행할지 효과적으로 결정해야 합니다. 2) CRS는 다양한 하위 작업을 숙련되게 처리할 필요가 있습니다. CRS는 특정 하위 작업을 설계하고 최적화하여 성능을 향상시킬 수 있어야 합니다. 그리고 3) CRS는 우수한 언어 생성 능력을 가져야 합니다. CRS는 사용자에게 유창하고 일관되며 의미 있는 응답을 생성해야 합니다.
최근 대규모 언어 모델(LLM)이 보여준 뛰어난 이해와 생성 능력으로 인해 더 강력한 CRS를 만들 수 있는 새로운 가능성이 등장하였습니다. 몇 가지 초기 접근 방식은 LLM의 이해 능력을 사용하여 추천 모델의 결과를 재정렬하고, LLM의 생성 능력을 사용하여 생성된 응답을 향상시키는 것을 포함합니다. 그러나 이러한 방법들은 하위 작업 관리를 수행할 수 없으며 다양한 하위 작업을 효과적으로 처리할 수도 없어, 열등한 CRS를 초래합니다.
최근 LLM을 사용하여 작업 계획, 외부 도구 플러그인, 생성 등을 수행하는 몇 가지 발전에 영감을 받아, 우리는 LLMCRS라고 하는 CRS를 위한 새로운 프레임워크를 제안합니다. 이는 1) LLM을 사용하여 하위 작업을 효과적으로 관리하고, 2) LLM을 여러 하위 작업의 전문 모델과 협력하여 하위 작업 성능을 향상시키며, 3) 사용자에게 향상된 응답을 생성하기 위해 LLM을 언어 인터페이스로 사용합니다. LLMCRS의 첫 번째 도전 과제는 LLM이 하위 작업 관리를 동시에 향상시키고, 전문 모델과의 협력을 촉진하며, 응답 생성을 최적화할 수 있도록 워크플로를 정의하는 것입니다. LLMCRS의 두 번째 도전 과제는 시스템의 제어 가능성을 향상시키기 위해 워크플로에서 LLM이 구체적이고 원하는 출력을 효과적으로 생성하도록 지시하는 방법입니다. LLMCRS의 세 번째 도전 과제는 시스템의 전반적인 성능을 향상시키기 위해 대화형 추천 데이터에 LLM을 적응시키는 방법입니다.
구체적으로 첫 번째 도전 과제를 위해, LLMCRS의 워크플로는 하위 작업 감지, 모델 매칭, 하위 작업 실행, 응답 생성의 네 단계로 나뉘며, 이는 그림 2에서 보여주듯이 하위 작업 관리를 동시에 향상시키고, 전문 모델과의 협력을 촉진하며, LLM에 의한 응답 생성을 최적화합니다. 두 번째 도전 과제를 위해, LLMCRS는 각 단계에서 다른 메커니즘을 설계하여 LLM이 원하는 결과를 효과적으로 생성하도록 지시합니다. 1) 작업 감지 단계에서 LLMCRS는 스키마 기반 지시 및 데모 기반 지시를 사용하여 LLM이 하위 작업 감지 기준을 이해하도록 지시합니다. 2) 모델 매칭 단계에서 LLMCRS는 동적 하위 작업 및 모델 매칭 메커니즘을 사용하여 LLM이 하위 작업에 적합한 전문 모델을 선택하도록 지시합니다. 3) 작업 실행 단계에서 LLMCRS는 하이브리드 추론 엔드포인트에서 선택된 전문 모델을 호출하여 하위 작업을 실행합니다. 4) 응답 생성 단계에서 LLMCRS는 요약 기반 생성을 사용하여 LLM이 이전 단계의 모든 정보를 통합하여 응답을 생성하도록 지시합니다. 세 번째 도전 과제를 위해, 우리는 RLPF라고 하는 새로운 방법을 제안합니다. 이는 CRS 성능 피드백에서 강화 학습을 활용하여 LLM을 대화형 추천 데이터에 적응시켜 성능을 향상시킵니다. RLPF는 추천 피드백 및 대화 피드백을 보상 신호로 사용하고 REINFORCE 방법을 사용하여 학습 방향을 안내합니다. 더 안정적인 업데이트와 학습을 이끌기 위해, 우리는 추정된 보상의 분산을 줄이는 기준 함수도 사용합니다.
GoRecDial 및 TG-ReDial 데이터셋과 같은 대화형 추천을 위한 두 개의 벤치마크 데이터셋에서 실험을 수행합니다. 실험 결과, LLMCRS는 기존 방법에 비해 추천 성능이 크게 우수하며 더 만족스러운 자연어 상호 작용을 제공합니다. 광범위한 분석은 하위 작업 관리의 중요성, 하위 작업의 전문 모델과 협력하는 영향, CRS 성능 피드백에서 강화 학습을 활용하는 효과, 그리고 LLM을 위한 지시 메커니즘의 효과를 밝힙니다. 요약하자면, 우리의 기여는 다음과 같습니다:
• 우리는 CRS의 도전 과제를 해결하기 위해 LLM을 효과적으로 활용하는 새로운 프레임워크 LLMCRS를 제안합니다. 이에는 하위 작업 관리, 숙련된 하위 작업 처리, 그리고 고급 언어 생성이 포함됩니다.
• LLMCRS는 CRS를 위한 새로운 워크플로를 정의하고 이 워크플로 내에서 LLM을 효과적으로 지시하는 다양한 메커니즘을 설계합니다.
• LLMCRS는 CRS 성능 피드백(RLPF)의 강화 학습으로 정제되어 성능이 향상됩니다.
• LLMCRS의 실험 결과는 기준치에 대한 최고의 성능을 달성하며 더 나은 자연어 상호 작용을 제공합니다. 광범위한 실험 분석은 또한 우리 방법의 장점을 더 잘 이해하는 데 도움이 됩니다.
2 RELATED WORK
2.1 Conversational Recommender System
대화형 추천 시스템(CRS)은 대화형 상호 작용을 통해 추천 서비스를 제공하는 것을 목표로 합니다. CRS에는 주로 두 가지 유형이 연구되어 왔습니다: 속성 기반 CRS와 생성 기반 CRS입니다. 속성 기반 CRS는 사전 정의된 행동을 통해 사용자와 상호 작용합니다. 이들은 아이템 속성에 대한 질의를 통해 사용자 선호도를 포착하고 사전 정의된 템플릿을 사용하여 응답을 생성합니다. 주로 가능한 한 적은 턴 내에 사용자 선호를 포착하고 정확한 추천을 제공하는 데 중점을 둡니다. 반면, 생성 기반 CRS는 더 자유 형식의 자연어 대화를 통해 사용자와 상호 작용합니다. 이들은 대화 맥락에서 선호도를 포착한 다음 자유 형식으로 응답을 생성합니다. 주로 자연어 인터페이스를 통해 정확한 추천을 제공하는 데 중점을 둡니다. 이러한 접근 방식은 종종 엔드 투 엔드 프레임워크를 활용합니다. 그러나 CRS의 복잡한 성격 때문에 그 효과가 제한됩니다. 본 연구에서는 생성 기반 CRS 유형에 초점을 맞추며, 복잡한 생성 기반 CRS를 개별 하위 작업으로 분해하여 각 개별 하위 작업의 성능을 향상시키는 것을 목표로 합니다.
2.2 LLMs for Recommendation
LLM이 자연어 처리에서 등장하면서 LLM을 활용하여 추천을 강화하는 데 대한 관심이 커지고 있습니다. LLM은 전통적인 추천 시스템과 대화형 추천 시스템, 두 가지 유형의 추천 시스템에 사용됩니다. 전통적인 추천은 주로 사용자의 과거 행동을 분석하여 사용자의 아이템에 대한 선호도를 예측합니다. 전통적인 추천을 위해 LLM을 특성 추출기로 활용하는 방안이 제안되었는데, 이는 아이템의 맥락과 사용자의 과거 행동을 LLM에 입력하여 해당하는 임베딩을 출력합니다. 일부 접근 방식은 LLM을 직접적인 추천 시스템으로 사용합니다. 입력 시퀀스는 일반적으로 사용자 프로필 설명, 아이템 설명, 그리고 상호 작용 이력으로 구성됩니다. 출력 시퀀스는 추천 아이템을 제공할 것으로 기대됩니다. 대화형 추천의 경우, 아직 초기 단계의 접근 방식만이 있습니다. 일부 연구자들은 추천 모델의 결과를 재정렬하기 위해 문맥 학습을 활용할 것을 제안합니다. 또 다른 연구자들은 응답을 생성하기 위해 프롬프팅 전략을 활용할 것을 제안합니다. 그러나 이들은 CRS의 분해 문제를 간과합니다. 본 연구에서는 대화형 추천에 초점을 맞추고 있으며, LLM을 사용하여 CRS를 하위 작업으로 분해하는 것을 목표로 합니다.
3 FRAMEWORK
LLMCRS는 LLM을 관리자로, 다수의 전문 모델을 협력 실행자로 구성된 협력적 대화형 추천 시스템입니다. LLMCRS의 워크플로는 네 단계로 구성되어 있으며, 이는 그림 2에서 보여집니다. 구체적으로, 1) LLM은 먼저 대화 맥락을 분석하여 현재 대화 턴에 실행해야 할 하위 작업을 그 지식에 기반하여 감지합니다; 2) LLM은 모델 설명에 따라 감지된 하위 작업을 적합한 전문 모델에 배분합니다; 3) 전문 모델은 할당된 하위 작업을 추론 엔드포인트에서 실행하고 실행 정보 및 추론 결과를 LLM에 반환합니다; 4) 마지막으로, LLM은 실행 정보 및 추론 결과를 요약하고 사용자에게 응답을 생성합니다.
3.1 Sub-Task Detection
LLMCRS의 첫 번째 단계에서 LLM은 대화 맥락을 입력으로 받아 현재 대화 턴에 실행해야 할 하위 작업을 감지합니다. 복잡한 대화형 추천 시스템은 종종 여러 하위 작업을 포함하며, 다양한 하위 작업은 다른 하위 작업 인자를 요구합니다. 스키마를 사용하여 다양한 하위 작업에 대한 통일된 템플릿을 제공할 수 있습니다. 또한, 시연을 통해 LLM이 더 나은 성능을 발휘하도록 지시할 수도 있습니다. 따라서, 다양한 작업을 통합하고 LLM이 하위 작업 감지 기준을 이해하는 능력을 향상시키기 위해 LLMCRS는 스키마 기반 지시와 시연 기반 지시를 프롬프트 디자인에 사용합니다. 해당 프롬프트는 표 2에 나와 있습니다. 다음 단락에서 세부사항을 소개합니다.
스키마 기반 지시: 스키마는 대화형 추천 시스템에서 다양한 하위 작업에 대한 통일된 템플릿을 제공하는 데 사용될 수 있습니다. LLMCRS는 하위 작업 감지를 위해 스키마에 세 개의 슬롯을 설계합니다. 이들은 하위 작업 이름, 하위 작업 인자, 그리고 출력 유형입니다:
- 하위 작업 이름: 하위 작업 감지를 위한 고유 식별자를 제공하며, 관련 전문 모델과 그들의 예측 결과를 참조하는 데 사용됩니다. LLMCRS에서 현재 지원되는 하위 작업 목록은 표 1에 나와 있습니다.
- 하위 작업 인자: 하위 작업 실행에 필요한 인자 목록을 포함합니다. 이들은 이전 대화 턴에서 실행된 하위 작업의 대화 맥락이나 예측 결과로부터 해결됩니다. 다양한 하위 작업에 대한 해당 인자는 표 1에 나와 있습니다.
- 출력 유형: 하위 작업의 출력 유형을 나타냅니다. 다양한 하위 작업에 대한 해당 출력 유형은 표 1에 나와 있습니다.
시연 기반 지시: 여러 시연을 프롬프트에 주입함으로써, LLMCRS는 대규모 언어 모델이 하위 작업 감지 기준을 더 잘 이해할 수 있도록 할 수 있습니다. 각 시연은 하위 작업 감지에 대한 입력과 출력 세트로 구성되며, 이들은 대화 맥락과 실행될 예정인 하위 작업입니다. 시연에서의 하위 작업은 스키마로 표현되며, 이는 LLM에 의해 추론됩니다. 시연은 LLMCRS가 하위 작업 감지 기준과 스키마의 슬롯의 의미를 이해하는 데 효과적으로 도움을 줍니다.
인스트럭션 튜닝과 인간 피드백에서의 강화 학습으로, 대규모 언어 모델은 지시를 따를 수 있는 능력을 가지고 있습니다. LLMCRS는 이러한 스키마 기반 지시와 시연 기반 지시를 대규모 언어 모델에 대화 맥락을 분석하고 그에 따라 하위 작업을 감지하는 고급 지시로 제공합니다.
3.2 Model Matching
하위 작업 감지 후, LLMCRS는 다음으로 해당 하위 작업과 전문 모델을 매칭해야 합니다. 즉, 하위 작업에 적합한 모델을 후보 전문 모델 세트에서 선택해야 합니다. LLMCRS가 후보 전문 모델 세트의 확장성을 가질 수 있도록, 우리는 동적 하위 작업 및 모델 매칭 메커니즘을 제안합니다. 이 메커니즘은 동적 후보 전문 모델 세트에서 모델을 선택할 수 있습니다. 이러한 접근 방법은 LLMCRS를 더 개방적이고 유연하게 만듭니다. 이에 대한 프롬프트는 표 2에 나와 있습니다. 다음 단락에서 세부사항을 소개합니다.
동적 하위 작업 및 모델 매칭: LLMCRS가 점진적으로 전문 모델에 접근할 수 있도록 하기 위해, 우리는 하위 작업 목표와 모델 설명 사이의 매칭 문제로서 하위 작업과 모델의 매칭을 접근합니다. 하위 작업과 전문 모델은 프롬프트에서 텍스트를 사용하여 제시됩니다. 새로운 전문 모델이 시스템에 추가될 때, 우리는 단순히 새로운 전문 모델 설명을 프롬프트에 추가하고 새 모델 설명과 하위 작업 목표 사이의 관련성을 분석합니다. 모델 설명은 일반적으로 개발자에 의해 제공되며, 기능, 아키텍처, 지원 언어, 도메인, 라이선스 등의 정보를 포함합니다. 이 정보는 LLM이 전문 모델의 기능을 이해하는 데 도움을 줄 수 있습니다. 따라서, 하위 작업을 그 목표로, 전문 모델을 모델 설명으로 프롬프트에서 제시함으로써, LLMCRS는 후보 전문 모델 세트에서 하위 작업에 적합한 모델을 선택하는 데 지원할 수 있습니다.
3.3 하위 작업 실행
하위 작업이 특정 전문 모델에 할당되면 다음 단계는 하위 작업을 실행하는 것입니다. 즉, 전문 모델 추론 과정을 수행합니다. 하위 작업 감지 단계에서 입력으로 받은 하위 작업 인자를 사용하여, 전문 모델은 하위 작업 출력을 계산한 다음 LLM에 그것을 보냅니다. 또한, 이 단계에서 전문 모델의 가용성 문제와 데이터 보안 문제를 해결하기 위해, 전문 모델은 온라인 API 호출과 로컬 추론 엔드포인트에서 실행되어야 합니다.
3.4 응답 생성
하위 작업 실행이 완료된 후, LLMCRS는 응답 생성 단계로 진입합니다. 사용자에게 응답을 생성하기 위해 LLM을 더 잘 지시하기 위해, LLMCRS는 대화 맥락과 이전 단계의 모든 정보를 LLM의 입력으로 사용해야 합니다. 따라서 우리는 요약 기반 생성 방식을 제안합니다. 이에 대한 프롬프트는 표 2에 나와 있습니다. 다음 단락에서 세부사항을 소개합니다.
요약 기반 생성: 이전 단계의 모든 정보를 통합하기 위해, LLMCRS는 요약을 LLM의 입력으로 사용합니다. 요약을 간결하게 만들기 위해, 우리는 다음과 같은 세 가지 속성을 포함하는 구조화된 형식으로 요약을 나타냅니다.
하위 작업 이름: 현재 대화 턴에 감지된 하위 작업.
전문 모델: 감지된 하위 작업에 선택된 전문 모델의 설명.
하위 작업 출력: 전문 모델의 추론 결과.
LLMCRS는 요약과 대화 맥빅을 입력으로 사용하여 LLM이 최종 응답을 생성하도록 합니다. 이는 이전 단계와 대화 맥락의 모든 정보를 효과적으로 통합할 수 있으며, LLM에 더 많은 지시를 제공하는 데 도움을 줍니다.
4 REINFORCEMENT LEARNING FROM CRSS PERFORMANCE FEEDBACK
학습에만 프롬프트를 사용하는 방법은 LLM을 지시하는 강력한 방법이지만, 대화 맥락과 추천 환경에 대한 더 깊은 이해가 필요한 실제 추천 문제를 해결하기에는 충분하지 않습니다. LLM의 이해 능력을 향상시킬 수 있는 잠재적인 방법 중 하나는 대화형 추천 문제에 대해 LLM을 미세 조정하기 위해 강화 학습 기술을 사용하는 것입니다. 본 연구에서는 추천 성능과 응답 생성 성능을 사용하여 LLM 학습을 안내하는 대화형 추천 시스템 성능 피드백에서의 강화 학습(RLPF)을 제안합니다. 이는 CRS의 전반적인 성능을 향상시키는 결과를 가져옵니다.
RLPF의 설정에서 환경은 제안된 LLMCRS 플랫폼이고, 에이전트는 Θ로 매개변수화된 대규모 언어 모델 𝐿입니다. LLM에 의해 생성된 해결책 𝑆는 대화형 추천 문제를 해결하기 위해 사용되는 행동으로 간주될 수 있습니다. 우리는 해당 데이터셋의 성능을 보상 신호로 사용할 수 있습니다. 표 2에서 LLMCRS의 프롬프트 디자인 세부사항을 보여줍니다. 프롬프트에는 하위 작업 목록, 하위 작업 스키마, 시연, 대화 맥락, 하위 작업 목표, 전문 모델, 하위 작업 출력과 같은 삽입 가능한 슬롯이 있습니다. 이러한 슬롯들은 LLM에 입력되기 전에 해당 텍스트로 일관되게 대체됩니다.
이러한 접근 방법을 통해 LLM은 강화 학습을 통해 보다 동적이고 적응적인 방식으로 대화형 추천의 복잡한 문제를 효과적으로 해결할 수 있는 능력을 개발할 수 있습니다. 추천과 응답 생성의 개별적인 성능을 기반으로 학습 과정을 조정함으로써, LLM은 실제 사용자의 요구와 반응에 더욱 잘 맞춰진 맞춤형 추천을 생성할 수 있게 됩니다. 이는 전통적인 감독 학습 접근법이 제공하지 못하는 상호작용과 개인화 수준을 가능하게 합니다.
5. 실험
5.1 데이터셋
대화형 추천을 위한 벤치마크 데이터셋인 GoRecDial과 TG-ReDial을 사용하여 실험을 수행합니다. 데이터셋의 소개는 다음과 같습니다.
GoRecDial: Kang et al.에 의해 발표된 대화형 추천 데이터셋입니다. 이 데이터셋은 Amazon Mechanical Turk(AMT)를 인터페이스로 사용하는 ParlAI를 통해 구축되었습니다. 실제 사용자의 영화 선호도를 반영하기 위해, 이 데이터셋은 MovieLens 데이터셋을 사용하여 58K개의 영화에 대한 27M개의 평가를 포함하는 추천 영화 풀을 구축했습니다. 영화 정보를 얻기 위해, Wikipedia에서 각 영화의 설명 텍스트를 얻고 MovieWiki 데이터셋을 사용하여 엔티티 수준의 특징(예: 감독, 배우, 연도)을 추출했습니다. GoRecDial의 통계는 표 3에 제시되어 있습니다.
TG-ReDial: Zhou et al.에 의해 발표된 대화형 추천 데이터셋입니다. 대화는 합리적이고 통제 가능한 인간 주석 노력을 포함하는 반자동 방식으로 생성되었습니다. 영화 관람 기록은 Douban 웹사이트에서 실제 사용자로부터 수집되었습니다. 이 데이터셋은 평균적으로 각 사용자당 202.7개의 관람 기록을 가진 1,482명의 사용자를 포함합니다. 영화 정보는 Douban에서 영화 태그(예: 장르, 감독, 주연)를 통해 추출되었습니다. TG-ReDial의 통계는 표 3에 제시되어 있습니다.
5.2 기준선
우리는 [3, 44, 46]을 따라 우리의 방법의 우수성을 평가하기 위해 다음과 같은 대표적인 기준선을 고려합니다:
BERT: 대규모 일반 말뭉치에서 마스크 언어 모델링 작업을 통해 사전 훈련된 양방향 언어 모델입니다. 추천을 위해 [CLS] 토큰의 표현을 사용합니다.
5.3 평가 척도
기존 연구를 따라, 추천 및 대화의 성능을 평가하기 위해 다양한 척도를 사용합니다. 추천의 경우, 생성된 추천 목록의 순위 성능을 측정하기 위해 HIT@k, MRR@k, NDCG@k (k=1, 10, 50)과 같은 순위 기반 척도를 개발합니다. 대화의 경우, 생성된 응답의 성능을 측정하기 위해 관련성 기반 및 다양성 기반 평가 척도를 모두 사용합니다. 관련성 기반 척도로는 BLEU가 있으며, 이는 기존 응답과 생성된 응답 사이의 유사성을 확률 관점에서 측정합니다. 다양성 기반 척도로는 Distinct가 있으며, 생성된 응답에서 다양한 단어의 수를 측정합니다.
5.4 구현 세부 사항
공정한 비교를 위해 모든 기준선과 LLMCRS를 오픈소스 툴킷 CRSLab을 사용하여 구현합니다. 기준선의 하이퍼파라미터 설정은 CRSLab에서 최고의 성능을 내는 기본 설정을 따릅니다. 데이터 전처리도 CRSLab의 것과 일치하여 공정하고 동등한 비교를 보장합니다. LLMCRS에서 사용하는 전문 모델은 각 작업에 대한 최신 방법입니다. 특히, 사용자 선호도 도출 작업에는 KBRD 및 KGSF 방법을 사용하고, 추천 작업에는 TG-ReDial 방법을 사용하며, 설명 작업에는 KBRD 및 KGSF 방법을 사용합니다. 아이템 세부 검색 작업의 경우 결과가 데이터베이스에서 직접 검색되므로 전문 모델을 사용하지 않습니다.
6 실험 결과 및 논의
6.1 전반적인 성능
표 4, 5, 6, 7은 각각 GoRecDial 및 TG-ReDial 데이터셋에서 LLMCRS와 추천 및 대화의 기준선 성능을 보여줍니다. LLMCRS는 CRS에서 가장 중요한 성능인 추천에서 최신 성능을 달성했습니다. 기준선과 비교하여 관찰된 모든 개선 사항은 양측 t-검정(p < 0.05)에 따르면 통계적으로 유의미합니다. 또한 LLMCRS는 최첨단 시스템과 비교하여 더욱 만족스러운 언어 인터페이스를 제공합니다. 관련성 기반 대화 평가 지표에서 LLMCRS의 성능은 기준선과 유사합니다. 특히 LLMCRS는 대화에서 다양성 기반 평가 지표의 성능을 크게 향상시킬 수 있습니다. 이것은 LLMCRS가 실제 대화와의 일관성을 유지하면서 사용자에게 더 다양하고 유익한 응답을 생성하여 사용자와 시스템 간의 상호 작용을 개선한다는 것을 나타냅니다. LLMCRS의 전반적인 우수한 성능은 작업 계획, 도구 상호 작용, 언어 이해 및 언어 생성 능력이 뛰어난 LLM이 포함되어 있기 때문이라고 추측합니다. 다음 분석은 모델의 강점을 더 잘 이해할 수 있도록 제공합니다.
6.2 요인 분석
우리는 LLMCRS에 대한 요인 분석을 수행하여 하위 작업 관리 사용, 전문가 모델과의 협력, CRS 성능 피드백을 통한 강화 학습 사용의 세 가지 요인의 효과를 정량화했습니다. 결과는 LLMCRS의 위의 모든 요소가 대화형 추천에 필수적임을 나타냅니다.
하위 작업 관리 사용의 효과
하위 작업 관리의 효과를 조사하기 위해 시스템에서 하위 작업 관리를 제거한 LLMCRS-w/o M과 LLMCRS를 비교했습니다. LLMCRS-w/o M은 시스템에서 하위 작업 관리를 제거한 LLMCRS와 비교하여 TG-ReDial이라는 전문가 모델과만 상호 작용하며, 현재의 대화가 해결해야 할 하위 작업과 상관없이 TG-ReDial의 출력에 따라 응답을 생성합니다. 그림 3과 4는 HIT@10, MRR@10, NDCG@10, BLEU-1, Distinct-1 측면에서 GoRecDial 및 TG-ReDial 데이터셋에 대한 LLMCRS-w/o M의 결과를 보여줍니다. 결과에서 볼 수 있듯이 하위 작업 관리가 없으면 추천과 대화의 성능이 상당히 저하됩니다. 이는 어떤 하위 작업을 언제 수행해야 하는지 효과적으로 감지하는 하위 작업 관리가 대화의 과정을 더 잘 이해하고 CRS의 전반적인 성능을 향상시킬 수 있음을 나타냅니다.
전문가 모델과의 협력 효과
전문가 모델을 통합하는 효과를 검증하기 위해 전문가 모델을 사용하는 대신 LLM과 함께 각 하위 작업을 사용했습니다. 사용자 선호도 추출, 설명 및 항목 정보 검색을 위해 대화 컨텍스트를 LLM의 입력으로 직접 사용한 다음 LLM에서 생성한 응답을 결과로 사용합니다. 추천의 경우 후보 항목 세트가 방대하기 때문에 LLM의 입력으로 모든 것을 가져오는 것은 어렵습니다. 따라서 먼저 BERT [12]로 항목과 대화의 간결한 유사성을 계산하고 유사성 점수를 기반으로 관련성이 높은 상위 50개 항목을 선택합니다. 그런 다음 LLM은 소규모 후보자 집합, 유사성 점수 및 대화 컨텍스트를 입력으로 사용하여 권장 사항을 예측합니다. 그림 3과 4는 GoRecDial 및 TG-ReDial 데이터셋에서 LLMCRS-w/o E의 결과를 보여줍니다. 우리는 HIT@10, MRR@10, NDCG@10, BLEU-1 및 Distinct-1 측면에서 LLMCRS-w/o E의 성능이 LLMCRS와 비교하여 크게 감소한 것을 볼 수 있습니다. 이는 전문가 모델과의 협력이 LLMCRS가 LLM과 작업별 모델 사이의 다리를 형성하여 효과적인 지식 이전 및 성능 향상을 가능하게 함을 나타냅니다. 또한 플러그인 전문가 모델 메커니즘은 시스템에 새로운 전문가 모델을 동적으로 추가할 수 있어 CRS의 확장성과 유연성을 높여줍니다.
RLPF의 효과
CRS 성능 피드백(RLPF)을 통한 강화 학습의 효과를 분석하기 위해 시스템에서 강화 학습 메커니즘을 제거한 LLMCRS-w/o RL과 LLMCRS의 성능을 비교했습니다. 그림 3과 4는 HIT@10, MRR@10, NDCG@10, BLEU-1 및 Distinct-1 측면에서 GoRecDial 및 TG-ReDial 데이터셋에 대한 LLMCRS-w/o RL과 LLMCRS의 결과를 보여줍니다. RLPF 없이도 성능이 상당히 저하된 것을 관찰할 수 있습니다. RLPF 메커니즘은 LLM의 권장 능력과 응답 생성 전략을 효과적으로 개선하여 향상되고 보다 적응력 있는 CRS를 제공합니다. 우리는 이것이 대화형 추천 문제를 해결할 때 LLM이 학습하기 위해 입력 텍스트에만 의존하는 것이 불충분하기 때문이라고 생각합니다. 성능 피드백은 LLM의 학습 궤도를 조정하는 가치 있는 보조 정보를 제공하여 보다 정확한 권장 사항을 제공하고 보다 적절한 응답을 생성할 수 있도록 합니다. 또한 RLPF가 없으면 TG-ReDial의 성능이 ReDial에 비해 더 두드러지게 저하됩니다. 우리는 이 현상이 TG-Redial의 대화가 미리 정의된 주제 스레드를 사용하여 구성되기 때문이라고 추측합니다. 결과적으로 CRS가 특정 주제에 적응할 수 있는 능력이 향상된 성능을 달성하는 데 중요해집니다. 이 현상은 RLPF의 뛰어난 적응성을 더욱 보여줍니다.
6.3 LLM을 지시하는 메커니즘
LLM을 지시하는 메커니즘에는 스키마 기반 지시, 데모 기반 지시, 동적 하위 작업 및 모델 매칭, 요약 기반 생성이 포함됩니다. 우리가 접근할 수 있는 전문가 모델의 수가 제한되어 있기 때문에 동적 하위 작업 및 모델 매칭 메커니즘을 분석하지 않습니다. 우리의 분석은 나머지 세 가지 메커니즘에 주로 초점을 맞추고 있습니다. LLMCRS를 프롬프트에서 작업 스키마 설명을 제거하는 LLMCRS-w/o SI, 프롬프트에서 데모를 제거하는 LLMCRS-w/o DI 및 구조화된 요약 텍스트 대신 전문가 모델의 실행 결과에서 직접 응답을 생성하는 LLMCRS-w/o SG와 비교합니다. 표 8은 HIT@10, MRR@10, NDCG@10, BLEU-1, Distinct-1 측면에서 GoRecDial에 대한 이러한 방법의 결과를 보여줍니다. 결과에서 알 수 있듯이 프롬프트에 메커니즘이 없으면 추천과 대화의 성능이 상당히 저하됩니다. 이는 1) 스키마 기반 지침이 LLM을 더 잘 안내하기 위해 동일한 형식으로 서로 다른 작업을 통합할 수 있으며 또한 작업 간 지식 공유를 촉진할 수 있습니다. 2) 데모 기반 지침은 LLM에 더 가까운 대화형 추천 작업을 만들기 위해 분포 내 대화형 추천 데모를 조건으로 만들 수 있으며 데모는 또한 입력 레이블 쌍의 형식을 유지할 수 있습니다. 3) 요약 기반 생성은 이전 단계의 모든 정보를 통합하고 향상된 응답 생성을 위해 LLM에 전역 지침을 제공합니다.
대화
사용자(U): 나는 다양한 종류의 영화를 좋아해. 드라마와 코미디도 좋아.
시스템(S): 좋아하는 감독이 있나요?
사용자(U): 로버트 저메키스나 스콜세지도 좋아.
시스템(S): 전쟁 드라마를 좋아하시나요?
사용자(U): 드라마.
응답
실제 응답: 쉰들러 리스트를 추천합니다. 감독 스타일 측면에서 스콜세지와 유사해 보입니다. 그리고 당신은 드라마를 좋아합니다.
TG-ReDial: 리틀 미스 선샤인을 추천합니다. 감독이 스콜세지와 비슷합니다.
LLMCRS: 쉰들러 리스트를 추천합니다. 감독 스타일이 스콜세지와 가장 유사해 보입니다. 그리고 훌륭한 드라마입니다. 이야기가 잘 만들어졌고 결말이 예상치 못한 곳으로 흘러갑니다.
그림 5: LLMCRS 사례 연구
6.4 사례 연구
우리는 LLMCRS와 GoRecDial 데이터셋의 기준선인 TG-ReDial의 결과에 대해 정성적 분석을 합니다. LLMCRS는 정확한 추천을 제공하고 더 유익한 응답을 생성할 수 있음을 발견합니다. 예를 들어 그림 5에서 LLMCRS는 사용자의 선호도 추출 작업에 대한 이전 턴의 전문가 모델 결과인 "Robert Zemeckis / Scorsese" 및 "Dramas"를 조정하여 사용자를 "Schindler's list"로 추천할 수 있습니다. LLMCRS는 LLM의 언어 이해 및 생성 능력을 활용하여 "It is a fantastic drama", "It’s story is well-crafted, and the ending is unexpected"와 같은 더 유익하고 해석적인 응답을 생성할 수도 있습니다. 반면 TG-ReDial은 잘못된 추천을 합니다. 잠재적인 설명 중 하나는 TG-ReDial이 하위 작업을 관리하고 특정 하위 작업에 맞춤 솔루션을 제공할 수 있는 능력이 부족하다는 것입니다. 따라서 사용자 선호도를 정확하게 추출하고 정확한 권장 사항을 제공할 수 없습니다. 또한 TG-ReDial의 대화 능력은 LLM보다 열등하여 더 유익하고 자연스러운 응답을 생성할 수 없습니다.
7 결론
우리는 LLMCRS라 불리는 대화형 추천 시스템을 위한 새로운 프레임워크를 제안했습니다. 이 시스템은 LLM을 사용하여 서브태스크를 더 잘 관리하고 전문가 모델과 효과적으로 협력하며, 개선된 응답을 생성합니다. LLMCRS의 워크플로에는 서브태스크 감지, 모델 매칭, 서브태스크 실행 및 응답 생성이 포함됩니다. 각 단계에서 LLM에게 정확한 수행을 지시하기 위해 지시 학습과 컨텍스트 학습이 사용됩니다. 우리는 또한 CRSs의 성능 피드백을 활용한 강화 학습을 통해 LLM을 개선하여 더 정확한 추천을 제공하고 더 적절한 응답을 생성할 수 있게 합니다. LLMCRS는 대화형 추천을 위한 통제 가능하고 적응력이 있는 시스템입니다. 실험 결과는 LLMCRS가 GoRecDial과 TGReDial의 벤치마크 데이터셋에서 CRS의 최신 방법보다 상당히 뛰어나다는 것을 보여줍니다. 마지막으로, 최근 LLM의 급속한 발전이 학계와 산업에 큰 영향을 미쳤다는 점도 언급해야 합니다. 또한 우리 모델의 디자인이 전체 커뮤니티에 영감을 주고 LLM이 추천으로 나아갈 수 있는 새로운 길을 열어주기를 기대합니다.
8 윤리적 고려 사항
대화형 추천 시스템에 대한 윤리적 고려 사항은 중요합니다. 이러한 시스템은 사용자와 직접 상호 작용하고 사용자의 결정에 영향을 미치기 때문에 투명성, 공정성 및 사용자 프라이버시를 보장하는 것이 필수적입니다. 개인화된 추천을 제공하면서도 조작이나 차별을 피하는 균형을 찾는 것이 중요합니다. 데이터 수집 및 사용뿐만 아니라 데이터에 내재된 편향 가능성에도 세심한 주의를 기울여야 합니다. 또한 사용자 동의, 데이터 보안 및 개인과 사회에 미치는 잠재적 영향도 철저히 평가하고 해결해야 합니다. 윤리적 문제를 적극적으로 해결함으로써 개발자는 윤리적 원칙과 사회적 책임을 준수하면서 사용자 경험을 향상시킬 수 있습니다.
'논문&아티클 리뷰(LLM + RS)' 카테고리의 다른 글
| 구글 I/O - 2024년 5월 15일 (0) | 2024.05.16 |
|---|---|
| 프롬프트 엔지니어링 방법 (0) | 2024.05.08 |
| Two-Tower Networks and Negative Sampling in Recommender Systems (0) | 2024.05.07 |
| ReAct: 언어 모델에서 추론과 행동의 시너지 효과 (0) | 2024.05.07 |
| Recommender Systems in the Era ofLarge Language Models (LLMs) (2) | 2024.05.01 |



