## Environment : Anaconda-navigator
## Programming Language : Python 3
## Import Pandas
## import seaborn as sns
## import Numpy as np
## import matplotlib pyplot as plt
1. 데이터를 불러오기 및 데이터 전처리
2. 데이터 분석
3. 추천시스템
저번 글에 이어 데이터들 전처리를 진행하도록 하겠습니다.
이번에는 users_df 을 정리해보도록 하겠습니다.
데이터에 대한 정보를 보겠습니다.
print(users_df.info())
print('\n')
print(users_df.columns)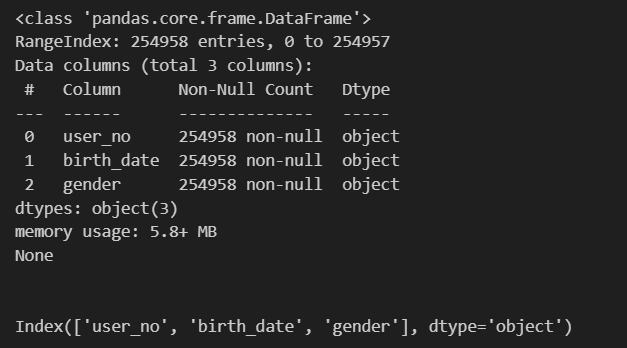
이번에는 성별 데이터를 다뤄보겠습니다.
users_df['gender'].unique() #un_gender는 결측치 처리할때 nan값을 처리한 값입니다
이번엔 성별 비율을 확인해보겠습니다.
print(users_df['gender'].value_counts())
print('\n')
print(users_df['gender'].value_counts(normalize=True))
상대적으로 여성분들의 비율이 높은걸 확인하실 수 있습니다.
이번에는 birth_date 컬럼의 데이터를 이용해서 age를 구해보도록 하겠습니다.
today = pd.Timestamp.now().floor('D')
users_df['birth_date'] = pd.to_datetime(users_df['birth_date'], errors='coerce')
users_df = users_df[~pd.isnull(users_df['birth_date'])]
users_df['age'] = ((today - users_df['birth_date']).dt.days / 365.25).astype(int)
users_df.head()
다음 페이지에서는 본 환경을 이어서 동일한 데이터를 가지고 추가적인 전처리를 진행하도록 하겠습니다.
반응형



