## Environment : Anaconda-navigator
## Programming Language : Python 3
## Import Pandas
## import seaborn as sns
## import Numpy as np
## import matplotlib pyplot as plt
1. 데이터를 불러오기 및 데이터 전처리
2. 데이터 분석
3. 추천시스템
저번 글에 이어 데이터들 전처리를 진행하도록 하겠습니다.
이번에는 product_df 을 정리해보도록 하겠습니다.
product_df.columns
category1_name 컬럼의 비율을 확인해 보겠습니다.
product_df['category1_name'].value_counts()
product_df['category1_name'].value_counts(normalize=True)
cat1_name = product_df['category1_name'].value_counts()
print(cat1_name) # 내용 확인
print('총 개수 = ',cat1_name.sum()) # 총합 확인
print('Others의 비율은 = ', cat1_name['의류'] / cat1_name.sum()) # 의류비율
시각화시 한글이 깨지기 때문에 한글을 안깨지게 합니다
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/malgun.TTF"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
시각화를 합니다.
plt.figure(figsize=[20, 5]) # 그래프의 크기 지정
sns.countplot(data = product_df, x='category1_name'\
, palette=sns.color_palette('coolwarm', 4)) # palette를 사용하여 그래프 bar 색 지정
category2_name 컬럼의 비율을 확인해 보겠습니다.
product_df['category2_name'].value_counts()
category3_name 컬럼의 비율을 확인해 보겠습니다.
product_df['category3_name'].value_counts()
brand_name 컬럼의 비율을 확인해 보겠습니다.
product_df['brand_name'].value_counts()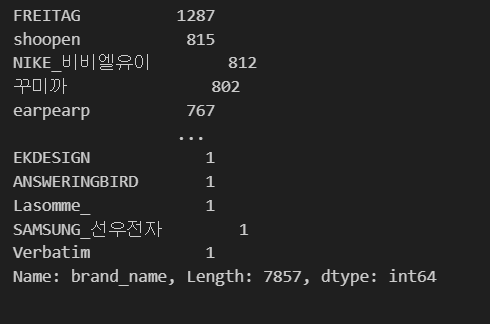
보통 가격의 100원 이하 데이터는 없기 때문에 100원이하 데이터를 확인해 본다
print(len(product_df[product_df['price'] <= 100]))
product_df[product_df['price'] <= 100].head()
price데이터에 100원 이하는 0원밖에 없다. 0원인 데이터는 큰 의미가 없고 15개의 데이터밖에 없기 때문에 drop한다
print(product_df[product_df['price'] <= 100].price.unique())
product_df = product_df[product_df['price'] != 0]
product_df.head()
다음 페이지에서는 본 환경을 이어서 동일한 데이터를 가지고 추가적인 전처리를 진행하도록 하겠습니다.
반응형



