## Environment : Anaconda-navigator
## Programming Language : Python 3
## Import Pandas
## import seaborn as sns
## import Numpy as np
## import matplotlib pyplot as plt
1. 데이터를 불러오기 및 데이터 전처리
2. 데이터 분석
3. 추천시스템
본격적으로 데이터 분석을 하기 전에 funnel 분석을 설명드리겠습니다.
- funnel은 깔때기란 뜻으로 funnel 분석은 깔때기의 원리와 유사합니다.
- 깔때기가 단계가 진행될 수록 좁아지면서 걸러지듯이 funnel 분석에서도 funnel 스탭에 따라 고객에 대한 분석이 가능합니다.
- funnel 분석은 단계에 따라 고객의 이탈률을 확인하여 그에 대한 조치를 가능하도록 도와주는 분석 방법이라 할 수 있습니다.
일별 활성 사용자(Active User) 수 구하기
활성 사용자 수는 방문수, 방문자수의 개념과는 달리 '정해진 기간동안 접속한 사용자의 수'입니다.
흔히 방문수를 구할때 사용하는 세션을 이용해 방문 횟수를 구하지만, 이는 실제 웹에 방문한 사용자 수와는 다른 개념입니다.
예를 들어 한명의 사용자가 한 사이트에 3번 접속했다면, 방문수는 3회이지만 활성 사용자수는 1명인 것입니다.


이런 활성 사용자는 DAU, WAU, MAU 등의 종류가 있는데, DAU는 Daily Active User로 일일 활성 사용자 수를 의미합니다.
WAU는 Weekly Active User, MAU는 Monthly Active User입니다.
우선 DAU 구해보겠습니다.
(전체적으로 데이터가 WAU, MAU를 구하기는 부족하다고 판단하였습니다)
데이터를 처음부터 불러와서 시작하겠습니다.
FILES_DIR = './files/'
total = pd.read_csv(FILES_DIR + 'total.csv')
total_df = total.copy()
본격적으로 DAU를 구해보겠습니다.
table_DAU = pd.pivot_table(total_df,
index='event_timestamp_month',
columns='event_timestamp_day',
values='user_no',
fill_value=0,
aggfunc=len)
table_DAU.T.sort_values(by=6, ascending=False)
월별로 총 DAU를 구해보겠습니다.
table_DAU['total'] = table_DAU.sum(axis='columns')
table_DAU.T
6월 평균 171646, 7월 평균 184097, 8월 평균 143981 을 확인했습니다.
사이트 체류 시간과 페이지 체류 시간
사이트 체류 시간은 말 그대로 사용자가 해당 사이트에 접속하여 머무른 시간을 얘기합니다. 그리고 페이지 체류 시간은 해당 사이트에 접속하여 하나의 페이지에 머무른 시간입니다.
페이지 체류 시간을 계산하는 방법은 간단합니다. 가장 최근의 페이지 방문 시간에서 이전 페이지 방문시간을 빼면 됩니다.
사이트 체류 시간은 페이지 체류 시간의 총합과 같습니다.


위의 사진과 같이 사용자가 페이지를 이동했다고 가정했을때 첫번째 페이지의 체류 시간은 3분, 두번째 페이지의 체류 시간은 4분입니다.
그러나 사이트 체류 시간은 10분이 아닌 7분으로 계산 된다는 점입니다. 사용자가 이탈하는 경우 세션 로그가 남지 않기 때문에 세번째 페이지의 체류 시간을 알 수 없고, 사이트 체류 시간 계산에 포함되지 않습니다.
그렇다고 해서 사이트/페이지 체류 시간이 유의미 하지 않은 지표는 아닙니다. 수많은 사용자들이 수많은 페이지를 빈번하게 오고가는 상황 속에 모든 로그에서 동일하게 마지막 페이지의 체류 시간을 계산하지 않기 때문에 모두가 일관된 기준으로 측정하기에 큰 문제가 되지 않습니다.
그리고 그 양이 상당하기 때문에 한개 페이지의 시간 차이는 크게 사용자들의 트렌드를 반영하지 못한다고 보는 것이 옳을 것입니다.
사이트 체류 시간 계산하기
위의 사이트 체류 시간의 개념을 적용하여 데이터셋을 이용하여 실제 사용자들의 사이트 체류 시간을 구해보겠습니다.
사용자들의 페이지 접속 시간을 확인하기 위해 세션 ID를 기준으로 합니다. 사용자의 경우 동일한 ID여도 세션이 다르면은 다른 경우로 간주해야 합니다.
왜냐하면 세션은 일정 시간동안 같은 사용자(정확하게는 브라우저)로 부터 들어오는 일련의 요구를 하나의 상태로 보기 때문에 세션이 달라졌다면은 다른 시간대에 접속한 것으로 보는 것이 맞기 때문입니다.
본격적으로 체류시간을 계산해보겠습니다.
동일한 세션에 대해 가장 마지막(최대)의 시간을 값으로 하는 그룹과 가장 처음(최소)의 시간을 값으로 하는 그룹 2개의 그룹을 만들고 이를 각각 데이터 프레임으로 생성해줍니다.
total_df['event_timestamp'] = pd.to_datetime(total_df['event_timestamp'])
total_df['event_timestamp'] = total_df['event_timestamp'].dt.strftime('%Y-%m-%d %H:%M:%S')
total_df['event_timestamp'] = pd.to_datetime(total_df['event_timestamp'])
max_group = total_df.groupby(['session_id', 'user_no'])['event_timestamp'].max()
min_group = total_df.groupby(['session_id', 'user_no'])['event_timestamp'].min()
max_time = pd.DataFrame(max_group)
max_time.columns = ['latest']
max_time
min_time = pd.DataFrame(min_group)
min_time.columns = ['start']
min_time
이후 2개의 데이터 프레임을 연결하여 준 뒤, 컬럼 간의 연산을 통해 세션별 사이트 체류 시간을 구해줍니다.
time_max_min = pd.concat([max_time, min_time], axis=1)
time_max_min['session_time'] = time_max_min['latest'] - time_max_min['start']
time_max_min.sort_values(by='session_time', ascending=False)
세션별 사이트 체류 시간의 히스토그램을 구해봅니다.
plt.figure(figsize=(12, 5))
sns.distplot(time_max_min.session_time)
평균, 표준편차, 중위값을 구해봅니다.
print(time_max_min.session_time.mean())
print(time_max_min.session_time.std())
print(time_max_min.session_time.median())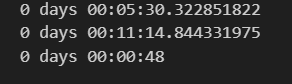
구매 데이터와 구매가 아닌데이터만 나뉘어서 체류시간을 비교해보겠습니다.
먼저 구매데이터 부터 보겠습니다.
suc_data = total_df[total_df['event_name'] == 'purchase_success']
suc_data['event_timestamp'] = pd.to_datetime(suc_data['event_timestamp'])
suc_data['event_timestamp'] = suc_data['event_timestamp'].dt.strftime('%Y-%m-%d %H:%M:%S')
suc_data['event_timestamp'] = pd.to_datetime(suc_data['event_timestamp'])
max_group = suc_data.groupby(['session_id', 'user_no'])['event_timestamp'].max()
min_group = suc_data.groupby(['session_id', 'user_no'])['event_timestamp'].min()
max_time = pd.DataFrame(max_group)
max_time.columns = ['latest']
min_time = pd.DataFrame(min_group)
min_time.columns = ['start']
suc_max_min = pd.concat([max_time, min_time], axis=1)
suc_max_min['session_time'] = suc_max_min['latest'] - suc_max_min['start']
suc_max_min.sort_values(by='session_time', ascending=False)
print(suc_max_min['session_time'].mean())
print(suc_max_min['session_time'].std())
print(suc_max_min['session_time'].median())
다른 이벤트 데이터 보겠습니다.
non_suc_data = total_df[total_df['event_name'] != 'purchase_success']
non_suc_data['event_timestamp'] = pd.to_datetime(non_suc_data['event_timestamp'])
non_suc_data['event_timestamp'] = non_suc_data['event_timestamp'].dt.strftime('%Y-%m-%d %H:%M:%S')
non_suc_data['event_timestamp'] = pd.to_datetime(non_suc_data['event_timestamp'])
max_group = non_suc_data.groupby(['session_id', 'user_no'])['event_timestamp'].max()
min_group = non_suc_data.groupby(['session_id', 'user_no'])['event_timestamp'].min()
max_time = pd.DataFrame(max_group)
max_time.columns = ['latest']
min_time = pd.DataFrame(min_group)
min_time.columns = ['start']
non_suc_max_min = pd.concat([max_time, min_time], axis=1)
non_suc_max_min['session_time'] = non_suc_max_min['latest'] - non_suc_max_min['start']
non_suc_max_min.sort_values(by='session_time', ascending=False)
print(non_suc_max_min['session_time'].mean())
print(non_suc_max_min['session_time'].std())
print(non_suc_max_min['session_time'].median())
평균의 차이가 5분정도 차이가 납니다.
이유를 생각해보면 구매하기전에는 고민을 하고 구매하겠다고 확신을 하면 바로 구매하기 때문에 차이는 당연히 난다고 생각합니다.
보다 중요한것은 구매를 확신했더라도 평균적으로 40초 정도 걸리고 많게는 5분정도 걸린다는것은 구매를 하는 과정이 생각보다 길다고 판단할수도있습니다.
또한 구매하지 않은 데이터들을 보면 평균적으로 고민을 5분30초정도 하고 많게는 16~17분정도 하는것을 볼수있습니다.
고민은 길게할수있지만 중위값으로 봤을때는 1분정도 안에 제품에대한 임펙트를 주는것이 좀더 좋은 해석인것같습니다.
무언가 제품의 설명이나 임펙트를 주고싶을때는 가독성 1분이상 가지 않게 하는것이 중요해 보입니다.
본격적으로 Funnel 분석을 하겠습니다.
분석에 필요한 컬럼만 불러와서 사용하겠습니다.
funnel_df = total_df[['user_no', 'event_name', 'event_timestamp']]
funnel_df
그리고 이 데이터 프레임에서 세션id와 이벤트 타임을 가지고 시간을 기준으로 하여 groupby를 진행해주겠습니다.
시간에 대해 최초 접속을 기준으로 하기위해 min으로 정렬하겠습니다.
funnel_group = funnel_df.groupby(['user_no', 'event_name'])['event_timestamp'].min()
funnel_group
다음 단계로는 funnel 스탭을 위한 별도의 데이터 프레임을 생성했습니다. 스탭은 순서대로 클릭, 좋아요, 장바구니, 구매 순으로 이어지도록 하였다.
funnel_steps = pd.DataFrame({'steps' : [1,2,3,4]}, index=['click_item', 'like_item', 'add_to_cart', 'purchase_success'])
funnel_steps
기존에 생성한 그룹을 데이터 프레임화 시켜준 후, funnel 스탭 데이터 프레임과 머지 시켜줍니다.
funnel_group = pd.DataFrame(funnel_group).merge(funnel_steps, left_on='event_name', right_index=True)
funnel_group
그 다음에는 피벗 테이블을 이용하여 세션 id별로 다음 단계로의 진행 여부를 확인할 수 있도록 구성해줍니다.
funnel = funnel_group.reset_index().pivot(index='user_no', columns='steps', values='event_timestamp')
funnel.columns = funnel_steps.index
funnel
이제 남은 것은 위의 데이터 프레임을 이용하여 단계별로 카운트하여 funnel 수치를 구해줍니다.
step_values = [funnel[column].notnull().sum() for column in funnel.columns]
step_values
그중에서도 plotly express를 이용하면 funnel 수치를 시각화합니다.
import plotly.express as px
data = dict(
number = [180605, 22599, 35383, 134741],
stage = ['click_item', 'like_item', 'add_to_cart', 'purchase_success'])
fig = px.funnel(data, x='number', y='stage')
fig.show()
클릭 대비 구매는 74%정도 이며 전체데이터 대비 구매율은 36%정도 됩니다.
여기서 DAU와 구매데이터가 연관성이 있는지 살펴보겠습니다
DAU가 가장 높은 날은 7월 11일입니다.
# 7월 11일
funnel_df_0711 = total_df[['user_no', 'event_name', 'event_timestamp','event_timestamp_month', 'event_timestamp_day']]
funnel_df_0711 = funnel_df_0711[funnel_df_0711['event_timestamp_month'] == 7]
funnel_df_0711 = funnel_df_0711[funnel_df_0711['event_timestamp_day'] == 11]
funnel_group_0711 = funnel_df_0711.groupby(['user_no', 'event_name'])['event_timestamp'].min()
funnel_steps_0711 = pd.DataFrame({'steps' : [1,2,3,4]}, index=['click_item', 'like_item', 'add_to_cart', 'purchase_success'])
funnel_group_0711 = pd.DataFrame(funnel_group_0711).merge(funnel_steps_0711, left_on='event_name', right_index=True)
funnel_0711 = funnel_group_0711.reset_index().pivot(index='user_no', columns='steps', values='event_timestamp')
funnel_0711.columns = funnel_steps_0711.index
step_values_0711 = [funnel_0711[column].notnull().sum() for column in funnel_0711.columns]
step_values_0711[18592, 1422, 2435, 4169]
import plotly.express as px
data = dict(
number = [18592, 1422, 2435, 4169],
stage = ['click_item', 'like_item', 'add_to_cart', 'purchase_success'])
fig = px.funnel(data, x='number', y='stage')
fig.show()
DAU가 가장 낮은 날은 8월 4일입니다.
# 8월 4일
funnel_df_0804 = total_df[['user_no', 'event_name', 'event_timestamp','event_timestamp_month', 'event_timestamp_day']]
funnel_df_0804 = funnel_df_0804[funnel_df_0804['event_timestamp_month'] == 8]
funnel_df_0804 = funnel_df_0804[funnel_df_0804['event_timestamp_day'] == 4]
funnel_group_0804 = funnel_df_0804.groupby(['user_no', 'event_name'])['event_timestamp'].min()
funnel_steps_0804 = pd.DataFrame({'steps' : [1,2,3,4]}, index=['click_item', 'like_item', 'add_to_cart', 'purchase_success'])
funnel_group_0804 = pd.DataFrame(funnel_group_0804).merge(funnel_steps_0804, left_on='event_name', right_index=True)
funnel_0804 = funnel_group_0804.reset_index().pivot(index='user_no', columns='steps', values='event_timestamp')
funnel_0804.columns = funnel_steps_0804.index
step_values_0804 = [funnel_0804[column].notnull().sum() for column in funnel_0804.columns]
step_values_0804[6157, 521, 837, 1339]
import plotly.express as px
data = dict(
number = [6157, 521, 837, 1339],
stage = ['click_item', 'like_item', 'add_to_cart', 'purchase_success'])
fig = px.funnel(data, x='number', y='stage')
fig.show()
7월 11일 데이터는 구매율 15%, 8월4일 구매율은 15% 즉 DAU와 구매율은 큰 연관성이 없다고 볼수있습니다.



